
”transformer 深度学习“ 的搜索结果

深度学习-一些关于transformer解读ppt
transformer详解


深度学习-Transformer实战系列视频教程,2022新课,目前市面上为数不多的关于Transformer的课程,希望对大家的学习有所帮助
深度学习中,transformer的简单理解。
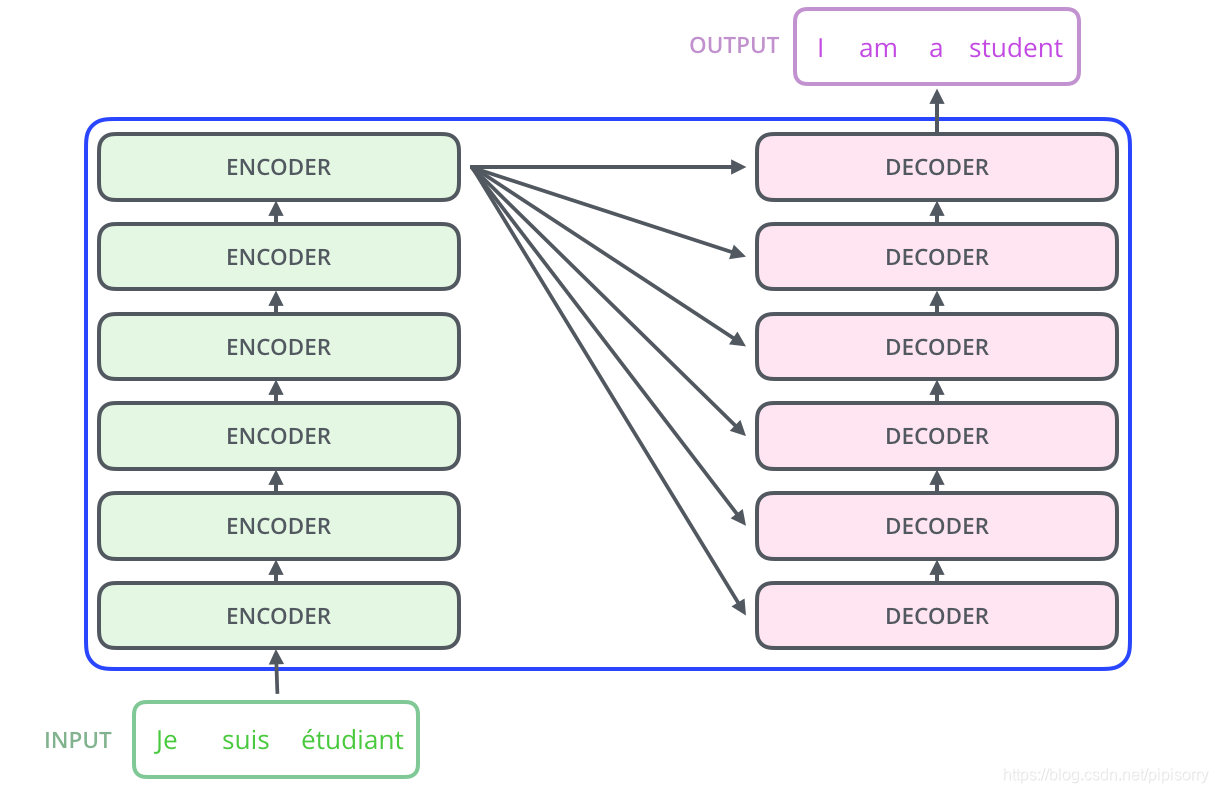

Transformer在深度学习环境下背景: 17年自Attention is all you need提出后,开始在NLP(自然语言处理)领域大放异彩 20年后,开始在CV领域发光,到现在基本一统天下了 其在NLP和CV领域下的许多分类、分割、检测等...
目前transformer在计算机视觉中非常火热,在面试过程中,也被面试官询问过相应内容,在此做一个简单的总结 self attention Transformer中的self attention和CV中的attention机制非常近似,都是通过建立一组输入数据...


深度学习自然语言处理-Transformer模型.zip

作者:禅与计算机程序...深度学习中的未来之星:Transformer模型及其在自然语言处理中的应用 作为一名人工智能专家,程序员和软件架构师,我认为 Transformer 模型在自然语言处理领域具有巨大的潜力和应用前景。Tran
知识点简介word
作者:禅与计算机程序设计艺术 《深度学习中的 Transformer 应用》 1. 引言 随着深度学习技术的快速发展,Transformer 模型的出现
Tranasformer实战系列课程旨在帮助同学们快速掌握当下Ai领域最火算法模型,通俗讲解transformer架构在NLP与CV领域的核心算法并基于真是数据集与实际任务展开项目实战。课程主要包括四大模块:1.算法讲解;2.论文分析...
3.Transformer模型 3.1.CNN与RNN的缺点: 1.CNNs 易于并行化,却不适合捕捉变长序列内的依赖关系。 2.RNNs 适合捕捉长距离变长序列的依赖,但是却难以实现并行化处理序列 3.2.为了整合CNN和RNN的优势,创新性地使用...

分享Transformer视频教程——Tranasformer实战系列课程旨在帮助同学们快速掌握当下Ai领域最火算法模型,通俗讲解transformer架构在NLP与CV领域的核心算法并基于真是数据集与实际任务展开项目实战。 课程主要包括...
给大家分享一套深度学习-Transformer实战系列视频课程,希望对大家学习有帮助,记得给五星好评哦
Transformer 深度学习模型
论文《FedTP: Federated Learning by Transformer Personalization》官方所附代码。 该论文提出了 FedTP,是一种基于 Transformer 的新型联邦学习框架,具有...适用于深度学习和联邦学习方面的研究者或爱好者收藏查看。
深度学习入门-4(机器翻译,注意力机制和Seq2seq模型,Transformer)一、机器翻译1、机器翻译概念2、数据的处理3、机器翻译组成模块(1)Encoder-Decoder框架(编码器-解码器)(2)Sequence to Sequence模型(3)集...
理解深度学习,包括最新的transformer和GNN


推荐文章
- withRouter,非根组件获取路由参数_withrouter 只能取到路由中的一个参数-程序员宅基地
- ubuntu环境下QT5操作摄像头报错,cannot find -lpulse-mainloop-glib cannot find -lpulse cannot find -lglib-2.0_cannot find–lpulse-程序员宅基地
- 用jbpm_bpel学jwsdp的ant方式使用-程序员宅基地
- 输入数字判断星期几_html获取当前星期几-程序员宅基地
- SpringBoot整合Activiti7——实战之放假流程(会签)_activit7中会签-程序员宅基地
- 阿里云服务器收到挖矿病毒的攻击,导致基础的文件被病毒污染的问题和对应的处理解决方法-程序员宅基地
- 北京东城区空调维修办法,格力变频空调出现ph,到底是怎么回事?_格力变频空调ph代码-程序员宅基地
- vscode编辑器使用拓展插件background添加背景图片改变外观_background vscode-程序员宅基地
- android 简单打电话程序_android拨打电话的程序-程序员宅基地
- 第二届中国(泰州)国际装备高层次人才创新创业大赛_泰州市双创人才计划2022-程序员宅基地